
Towards End-to-End Lane Detection: an Instance Segmentation Approach
Abstract
현대 자동차는 점점 더 많은 운전자 지원 기능을 통합하고 있으며 그중 자동 차선 유지 기능이 있습니다. 후자는 차량이 도로 차선 내에 적절하게 위치 할 수 있도록하는데, 이는 완전 자율 주행 차량의 후속 차선 이탈 또는 궤도 계획 결정에도 중요합니다. 기존의 차선 감지 방법은 고도로 전문화 된 수작업 기능과 휴리스틱스의 조합에 의존하며, 일반적으로 계산 비용이 많이 들고 도로 장면 변화로 인해 확장성에 취약한 후처리 기술이 뒤따릅니다. 보다 최근의 접근 방식은 큰 수용 필드로 인해 이미지에 표시가 없는 경우에도 픽셀 단위 레인 분할을 위해 훈련 된 딥 러닝 모델을 활용합니다. 장점에도 불구하고 이러한 방법은 미리 정의된 고정 된 수의 Ego lane을 감지하는 데 제한되고 차선 변경에 대처할 수 없습니다. 이 논문에서는 앞서 언급 한 한계를 넘어서 각 레인이 자체 인스턴스를 형성하는 인스턴스 분할 문제로 레인 감지 문제를 처리 할 것을 제안합니다. 차선을 맞추기 전에 분할 된 차선 인스턴스를 매개 변수화하기 위해 고정 된 "버드아이 뷰" 변환과 달리 이미지에 조건을 둔 학습된 원근 변환을 적용 할 것을 제안합니다. 이를 통해 사전 정의 된 고정 변환에 의존하는 기존 접근 방식과 달리 도로 평면 변경에 대해 강력한 차선 피팅을 보장합니다. 요약하면 50fps로 실행되는 빠른 차선 감지 알고리즘을 제안합니다. 이 알고리즘은 다수의 차선을 처리하고 차선 변경에 대처할 수 있습니다. 우리는 tuSimple 데이터 세트에서 방법을 확인하고 경쟁적인 결과를 얻습니다.
I. INTRODUCTION
완전 자율 주행 자동차는 오늘날 학업 및 산업 수준 모두에서 컴퓨터 비전 및 로봇 연구의 주요 포커스입니다. 각 경우의 목표는 다양한 센서와 제어 모듈을 사용하여 차량 주변 환경을 완전히 이해하는 것입니다. 카메라 기반 차선 감지는 차량이 도로 차선 내에 적절하게 위치 할 수 있도록하므로 이러한 환경 인식을 향한 중요한 단계입니다. 차선 이탈이나 경로 계획 결정에도 중요합니다. 따라서 실시간으로 정확한 카메라 기반 차선 감지를 수행하는 것이 완전 자율 주행의 핵심 요소입니다.
기존의 차선 감지 방법 (예 : [4], [9], [15], [17], [33], [35])은 차선 세그먼트를 식별하기 위해 고도로 전문화 된 수작업 기능과 휴리스틱스의 조합에 의존합니다. 이러한 수작업으로 만든 단서의 인기있는 선택에는 color-based features [7], structure tensor [25], bar filter [34], ridge features [26] 등이 있으며, 이는 허프 변환 [23][37] 및 particle 또는 칼만 필터 [18], [8], [34]와 결합 될 수 있습니다. 차선 세그먼트를 식별 한 후 후처리 기술을 사용하여 잘못된 감지를 필터링하고 세그먼트를 그룹화하여 최종 차선을 형성합니다. 차선 감지 시스템에 대한 자세한 개요는 [3]을 참조하십시오. 일반적으로 이러한 전통적인 접근 방식은 이러한 모델 기반 시스템에서 쉽게 모델링 할 수없는 도로 장면 변화로 인해 robustness issues가 발생하기 쉽습니다.
더 최근의 방법은 수작업으로 만든 기능 탐지기를 딥 네트워크로 대체하여 고밀도 예측, 즉 픽셀 단위 차선 분할을 학습합니다. Gopalan et al. [11]은 상황 정보를 모델링하기 위해 픽셀 계층 특징 설명자를 사용하고 차선 표시를 감지하기 위해 관련 상황 특징을 선택하기 위해 부스팅 알고리즘을 사용합니다. 비슷한 맥락에서 Kim과 Lee [19]는 Convolutional Neural Network (CNN)와 RANSAC 알고리즘을 결합하여 에지 이미지에서 시작하는 차선을 감지합니다. 그들의 방법에서 CNN은 주로 이미지 향상에 사용되며 도로 장면이 복잡한 경우에만 사용됩니다. 여기에는 가로수, 울타리 또는 교차로가 포함됩니다. Huval et al. [16]은 기존의 CNN 모델이 고속도로 주행 애플리케이션에 어떻게 사용될 수 있는지 보여줍니다. 그 중에서 차선 감지 및 분류를 수행하는 종단 간 CNN이 있습니다. He et al. [13]은 프론트뷰와 탑뷰 이미지를 동시에 사용하여 오탐지를 배제하고 클럽 모양이 아닌 구조를 각각 제거하는 Dual-View CNN (DVCNN)을 소개합니다. Li et al. [22]는 차선을 감지하는 RNN (Recurrent Neural Network)과 함께 위치 및 방향과 같은 기하학적 차선 속성을 찾는 데 초점을 맞춘 다중 작업 심층 컨볼 루션 네트워크의 사용을 제안합니다. 가장 최근에는 Lee et al. [21]이 다중 작업 네트워크가 악천후 및 낮은 조명 조건에서 차선 및 도로 표시 감지 및 인식을 공동으로 처리하는 방법을 보여줍니다. 앞서 언급 한 네트워크가 차선 표시를 더 잘 분할 할 수있는 능력과는 별도로 [16], 큰 수용 필드(big receptive field)를 통해 이미지에 표시가없는 경우에도 차선을 추정 할 수 있습니다. 그러나 최종 단계에서 생성 된 이진 레인 분할은 여전히 다른 레인 인스턴스로 분리되어야합니다.
이 문제를 해결하기 위해 일부 접근법은 예를 들어 [19], [12]에서 수행 된 것처럼 일반적으로 기하학적 속성에 의해 안내되는 휴리스틱에 다시 의존하는 후처리 기술을 적용했습니다. 위에서 설명한 것처럼 이러한 휴리스틱 방법은 계산 비용이 많이 들고 도로 장면 변화로 인해 견고성 문제가 발생하기 쉽습니다. 또 다른 작업 라인 [20]은 차선 탐지 문제를 각 차선이 고유 한 클래스를 형성하는 다중 클래스 분할 문제로 캐스팅합니다. 이렇게하면 네트워크의 출력에 각 레인에 대한 분리된 이진맵이 포함되고 종단간 방식으로 훈련 될 수 있습니다. 장점에도 불구하고이 방법은 미리 정의 된 고정 된 수의 차선, 즉 Ego lane만 감지하는 것으로 제한됩니다. 또한 각 차선에는 지정된 클래스가 있기 때문에 차선 변경에 대응할 수 없습니다.
본 논문에서는 앞서 언급 한 한계를 뛰어 넘어 각 레인이 레인 클래스 내에서 자체 인스턴스를 형성하는 인스턴스 분할 문제로 레인 감지 문제를 처리 할 것을 제안합니다. Semantic segmentation 및 instance segmentation 작업에서 밀도 예측 네트워크의 성공에 영감을 받아, 엔드투엔드를 훈련할 수 있는 lane segmentation branch와 lane embedding branch로 구성된 lane instance segmentation[27]과 같은 분기형 다중 태스크 네트워크를 설계합니다. Lane segmentation branch에는 배경 또는 레인의 두가지 출력 클래스가있는 반면, lane embedding branch는 분할된 레인 픽셀을 다른 레인 인스턴스로 추가로 분리합니다. 차선 감지 문제를 앞서 언급 한 두 가지 작업으로 분할하면 차선에 다른 등급을 할당하지 않고도 차선 분할 분기의 기능을 완전히 활용할 수 있습니다. 대신, 클러스터링 손실 함수를 사용하여 훈련 된 레인 임베딩 분기는 배경 픽셀을 무시하면서 레인 분할 분기의 각 픽셀에 레인 ID를 할당합니다. 이렇게함으로써 차선 변경 문제를 완화하고 [20]과 달리 다양한 수의 차선을 처리 할 수 있습니다.
레인 인스턴스, 즉 어떤 픽셀이 어떤 레인에 속하는지 추정 한 후 마지막 단계로 각각의 픽셀을 parametric description으로 변환하려고합니다. 이를 위해 커브 피팅 알고리즘이 문헌에서 널리 사용되었습니다. 인기있는 모델은 3차 다항식 [32], [25], 스플라인 [1] 또는 클로소이드 [10]입니다. 계산 효율성을 유지하면서 핏의 품질을 높이려면 원근 변환 [39]을 사용하여 이미지를 "버드아이뷰"로 변환하고 여기에서 커브 피팅을 수행하는 것이 일반적입니다. 버드아이뷰에서 피팅된 레인은 역변환 행렬을 통해 원본 이미지로 재투영 될 수 있습니다. 일반적으로 변환 행렬은 단일 이미지에서 계산되며 고정된 상태로 유지됩니다. 그러나 지상 평면이 형태가 변경되면 (예 : 오르막 경사로)이 고정 변환은 더 이상 유효하지 않습니다. 결과적으로 수평선에 가까운 차선 점이 무한대로 투영되어 선 맞춤에 부정적인 영향을 미칠 수 있습니다.
이 상황을 해결하기 위해 곡선을 맞추기 전에 이미지에 원근 변환을 적용하지만 원근 변환을 수행하기 위해 고정 변환 행렬에 의존하는 기존 방법과 달리 변환 계수를 출력하도록 신경망을 훈련합니다. 특히 신경망은 이미지를 입력으로 받아들이고 차선 맞춤 문제에 맞는 손실 함수로 최적화됩니다. 제안된 방법의 내재된 장점은 차선 피팅이 도로 평면 변경에 대해 견고하고 특히 차선을 더 잘 맞추기 위해 최적화된다는 것입니다. 전체 파이프 라인의 개요는 그림 1에서 볼 수 있습니다.

우리의 기여는 다음과 같이 요약 될 수 있습니다.
(1) 차선 변경을 처리하고 임의의 수의 차선을 추론 할 수있는 차선 감지 문제를 인스턴스 분할 작업으로 캐스팅하는 분기 된 다중 작업 아키텍처. 특히, 레인 분할 분기는 조밀한 픽셀당 레인 세그먼트를 출력하는 반면, 레인 임베딩 분기는 분할된 레인 픽셀을 다른 레인 인스턴스로 추가로 분리합니다.
(2) 입력 이미지를 받은 네트워크는 도로 평면 변화 (예 : 오르막 / 내리막 경사)에 대해 견고한 차선 맞춤을 허용하는 원근 변환의 매개 변수를 추정합니다.
논문의 나머지 부분은 다음과 같이 구성됩니다. 섹션 II에서는 시맨틱 및 인스턴스 레인 분할을 위한 파이프 라인을 설명하고 분할된 레인 인스턴스를 파라 메트릭 라인으로 변환하는 방법을 설명합니다. 제안된 파이프 라인의 실험 결과는 섹션 III에 나와 있습니다. 마지막으로 섹션 IV가 우리 작업을 마칩니다.
II. METHOD
앞서 언급 한 차선 변경 문제와 차선 수에 대한 제한 사항을 처리하는 방식으로 차선 감지를 위해 neural network end-to-end를 훈련합니다. 이는 차선 감지를 인스턴스 분할 문제로 처리하여 달성됩니다. LaneNet (그림 2 참조)이라고하는 네트워크는 이진 레인 분할의 이점과 one-shot instance segmentation을 위해 설계된 클러스터링 손실 기능을 결합합니다. LaneNet의 출력에서 각 레인 픽셀에는 해당 레인의 ID가 할당됩니다. 이것은 섹션 II-A에서 자세히 설명합니다.

LaneNet은 레인 당 픽셀 모음을 출력하므로 레인 매개 변수화를 얻으려면 여전히 이러한 픽셀을 통해 곡선을 맞춰야합니다. 일반적으로 레인 픽셀은 고정된 변환 행렬을 사용하여 "버즈아이 뷰" 방식으로 먼저 투영됩니다. 그러나 변환 매개 변수가 모든 이미지에 대해 고정되어 있기 때문에 슬로프같은 평평하지 않은 지면이 발생할 때 문제가 발생합니다. 이 문제를 완화하기 위해 입력 이미지에 따라 "이상적인" 원근 변환의 매개 변수를 추정하는 H-Net이라고하는 네트워크를 훈련시킵니다. 이러한 변화가 반드시 일반적인 "버즈아이 뷰"는 아닙니다. 대신 차선이 저차 다항식에 최적으로 맞춰질 수있는 변환입니다. 섹션 II-B는이 절차를 설명합니다.
A. LANENET
LaneNet은 레인 감지를 인스턴스 세분화 문제로 처리하여 레인 감지를 위한 엔드 투 엔드 트레이닝을 받았습니다. 이렇게하면 네트워크가 감지 할 수 있는 레인 수에 제한을 받지 않고 차선 변경에 대처할 수 있습니다. Instance segmentation task는 segmentation 및 클러스터링 두 부분으로 구성되며 다음 섹션에서 자세히 설명합니다. 속도와 정확성 측면에서 성능을 높이기 위해 [27]이 두 부분은 멀티 태스크 네트워크에서 공동으로 훈련됩니다 (그림 2 참조).
binary segmentation
LaneNet의 segmentation branch(그림 2, 하단 분기 참조)는 이진 세분화 맵을 출력하도록 훈련되어 어떤 픽셀이 레인에 속하는지 여부를 나타냅니다. Ground-Truth Segmentation 맵을 구성하기 위해 모든 Ground-Truth 레인 포인트를 함께 연결하여 레인 당 연결된 선을 형성합니다. 이러한 Ground-Truth 차선은 자동차가 가리고 있거나 점선 또는 희미한 차선과 같은 명시적인 시각적 차선 세그먼트가없는 경우에도 그립니다. 이런 식으로 네트워크는 차선이 가려 지거나 불리한 상황에서도 차선 위치를 예측하는 방법을 학습합니다. 세분화 네트워크는 표준 교차 엔트로피 손실 함수로 훈련됩니다. 두 클래스 (레인 / 배경)가 매우 불균형하므로 [29]에 설명 된대로 제한된 역 클래스 가중치를 적용합니다.
instance segmentation
Segmentation branch에 의해 식별된 레인 픽셀을 분류하기 위해 레인 인스턴스 임베딩을 위한 LaneNet의 두 번째 분기를 훈련합니다 (그림 2, 상단 분기 참조). 가장 널리 사용되는 detect-and-segment 접근 방식 (예 : [14], [38])은 레인 인스턴스 분할에 적합하지 않습니다. Bounding box 감지는 레인이 아닌 소형 객체에 더 적합하기 때문입니다. 따라서 우리는 De Brabandere 등이 제안한 거리 측정 학습에 기반한 one-shot method를 사용합니다. [5] 표준 피드 포워드 네트워크와 쉽게 통합 될 수 있으며 실시간 애플리케이션을 위해 특별히 설계되었습니다.
클러스터링 손실 함수를 사용하면 인스턴스 임베딩 브랜치가 각 레인 픽셀에 대한 임베딩을 출력하도록 훈련되어 동일한 레인에 속하는 픽셀 임베딩 사이의 거리가 작은 반면 다른 레인에 속하는 픽셀 임베딩 사이의 거리는 최대화됩니다. 이렇게하면 동일한 레인의 픽셀 임베딩이 함께 클러스터링되어 레인 당 고유 한 클러스터를 형성합니다. 이는 차선의 평균 임베딩쪽으로 각 임베딩에 pull force를 적용하는 variance term(L_var)과 클러스터 중심을 서로 멀리 밀어내는 distance term(L_dist)이라는 두 용어의 도입을 통해 달성됩니다. 두 항 모두 힌지가 적용됩니다. pull force은 임베딩이 클러스터 중심에서 δv보다 멀 때만 활성화되고 중심 사이의 push force은 δd보다 서로 가까울 때만 활성화됩니다. C는 클러스터 (레인) 수, N_c는 클러스터 c의 요소 개수, x_i는 픽셀 임베딩, µ_c는 클러스터 c의 평균 임베딩, ll · ll는 L2 거리, [x]_+ = max(0, x) 힌지, 총 손실 L은 L_var + L_dist와 같습니다.

네트워크가 수렴되면 레인 픽셀의 임베딩이 함께 클러스터링되어 (그림 2 참조) 각 클러스터가 서로 δ_d보다 멀어지고 각 클러스터의 반경이 δ_v보다 작습니다.
clustering
클러스터링은 반복적인 절차에 의해 수행됩니다. 위의 손실에서 δ_d > 6δ_v를 설정하면 동일한 레인에 속하는 모든 임베딩을 선택하기 위해 반경 2δ_v의 임의 레인 임베딩 및 임계 값을 사용할 수 있습니다. 모든 레인 임베딩이 레인에 할당 될 때까지 반복됩니다. Outlier 값을 threshold로 선택하지 않으려면, 먼저 평균 이동을 사용하여 클러스터 중심에 더 가깝게 이동한 다음 임계 값을 지정합니다 (그림 2 참조).
network architecture
LaneNet의 아키텍처는 인코더-디코더 네트워크 ENet [29]을 기반으로하며 결과적으로 두 개의 분기 네트워크로 수정됩니다. ENet의 인코더에는 디코더보다 더 많은 매개 변수가 포함되어 있기 때문에 두 작업간에 전체 인코더를 완전히 공유하면 만족스럽지 못한 결과가 발생할 수 있습니다 [27]. 따라서 원래 ENet의 인코더는 3단계 (1, 2, 3 단계)로 구성되지만 LaneNet은 두 분기 사이에서 처음 두단계(1과 2)만 공유하고 각 개별 분기의 백본으로 ENet 인코더의 3단계와 전체 ENet 디코더를 남깁니다. 분할 브랜치의 마지막 레이어는 1채널 이미지(이진 분할)를 출력하는 반면 임베딩 브랜치의 마지막 레이어는 N이 임베딩 차원인 N채널 이미지를 출력합니다. 이것은 그림 2에 개략적으로 묘사되어 있습니다. 각 분기의 손실 기간은 동일하게 가중치가 부여되고 네트워크를 통해 역 전파됩니다
B. CURVE FITTING USING H-NET
이전 섹션에서 설명한대로 LaneNet의 출력은 레인 당 픽셀 모음입니다. 기존의 이미지 공간에서 이러한 픽셀로 다항식을 맞추는 것은 이상적이지 않습니다. 곡선 차선에 대처하기 위해 고차 다항식에 의존해야하기 때문입니다. 이 문제에 대해 자주 사용되는 솔루션은 이미지를 "bird’s-eye view"표현으로 투영하는 것입니다. 여기서 차선은 서로 평행하므로 곡선 차선은 2차에서 3차 다항식으로도 적당 할 수 있습니다. 그러나 이러한 경우 변환 행렬 H는 한 번 계산되고 모든 이미지에 대해 고정 된 상태로 유지됩니다. 일반적으로 이로 인해 무한대로 투영되는 소실점이 위아래로 이동하는 지면 변경시 오류가 발생합니다 (그림 4, 두 번째 행 참조). 이 문제를 해결하기 위해 사용자 지정 손실 함수를 사용하여 신경망 H-Net을 훈련시킵니다. 네트워크는 원근 변환 H의 매개 변수를 예측하기 위해 end-to-end로 최적화되며, 변환된 차선 포인트는 2차 또는 3차 다항식에 최적으로 맞춰질 수 있습니다. 예측은 입력 이미지에 따라 조정되므로 네트워크가 지상 평면 변경시 투영 매개 변수를 조정할 수 있으므로 차선 피팅이 여전히 정확합니다 (그림 4의 마지막 행 참조). 우리의 경우 H는 6 개의 자유도를가집니다.

'0'은 변환시 수평선이 수평으로 유지되는 제약 조건을 적용하기 위해 배치됩니다.
curve fitting
차선 픽셀 P를 통해 커브 피팅하기 전, 후자는 H-Net의 아웃풋 transformation matrix를 사용하여 변환됩니다. 차선 픽셀 p_i(pi = [xi , yi , 1]T ∈ P)가 주어지면 변환된 픽셀 p'_i([P'_i = x_i , y_i , 1]T ∈ P')는 Hp_i와 같습니다. 다음으로 최소 제곱 알고리즘은 변환된 픽셀 P'을 통해 n차 다항식 f(y')를 피팅하는데 사용합니다. 주어진 y-좌표에 있는 차선의 x-좌표 x*_i를 얻기 위해, 점 p_i = [−, yi , 1]T는 p'_i = Hp_i = [−, yi , 1]T로 변환되고 다음과같이 계산됩니다: x'*_i = f(y'_i). x-value는 중요하지 않으며 '-'로 표시됩니다. 점 p'*_i = [x'*_i, y'_i, 1]T를 원래 이미지 공간으로 재투영하면 p*_i = H(-1)p'*_i with p*_i = [x*_i, y_i, 1]T가 됩니다. 이렇게하면 서로 다른 y 위치에서 차선을 평가할 수 있습니다. 이 프로세스는 그림 3에 나와 있습니다.

loss function
차선 픽셀을 통해 다항식을 맞추기에 최적인 변환 행렬을 출력하도록 H-Net을 훈련시키기 위해 다음과 같은 손실 함수를 구성합니다. N개의 GT 차선 점 p_i = [x_i, y)i, 1]T ∈ P가 주어지면 먼저 H-Net의 출력을 사용하여 점을 변환합니다:


이러한 투영된 점을 통해 최소 제곱 닫힌형태 해를 사용하여 다항식 f(y') = αy'^2 + βy' + γ를 피팅합니다.

피팅된 다항식은 각 y'_i 위치에서 평가되어 x'*_i 예측값을 제공합니다. 이러한 예측값은 다시 투영됩니다. p∗_i = H(-1)p'∗_i with p∗_i = [x∗_i , y_i , 1]T and p'∗_i = [x'∗_i , y'_i , 1]T. 손실은 다음과 같습니다.:

차선 피팅은 최소 제곱 알고리즘의 닫힌-형태 해를 사용하여 수행되므로 손실을 미분 할 수 있습니다. 기울기를 계산하기 위해 자동 미분을 사용합니다.
network architecture
H-Net의 네트워크 아키텍처는 의도적으로 작게 유지되며 3x3 컨볼루션, batchnorm 및 ReLU의 연속 블럭으로 구성됩니다. max pooling layer를 사용하여 차원이 감소되고 결국 2개의 fully-connected layer가 추가됩니다. 전체 네트워크 구조는 표 I를 참조하십시오.

III. RESULTS
A. Dataset
현재 tuSimple 레인 데이터 세트[40]는 레인 감지 작업에서 딥러닝 방법을 테스트하기위한 유일한 대규모 데이터 세트입니다. 그것은 좋은 기상 조건에서 3626개의 트레이닝 이미지와 2782개의 테스트 이미지로 구성되어 있습니다. 그들은 다른 주간에 2차선/3차선/4차선 또는 그 이상의 고속도로 도로를 기록하고 있습니다. 각 이미지에 대해 주석이 추가되지 않은 19개의 이전 프레임도 제공합니다. 주석은 여러 이산화 된 y-좌표에서 레인의 x-좌표를 나타내는 json 형식으로 제공됩니다. 각 이미지에는 현재(Ego)차선과 왼쪽 / 오른쪽 차선이 주석으로 표시되며 이는 테스트 세트에서도 예상됩니다. 차선을 변경할 때 혼동을 피하기 위해 5번째 차선을 추가 할 수 있습니다.
정확도는 이미지 당 평균 정확한 점들의 수로 계산됩니다:

C_im은 정확한 포인트의 수를, S_im은 GT 포인트의 수를 계산합니다. GT값과 예측 포인트의 차이가 특정 임계값보다 작을 때 포인트가 정확합니다. 정확성과 함께 false positive and false negative scores도 제공합니다.
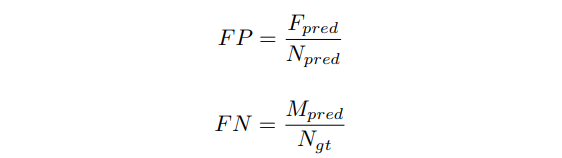
F_pred는 잘못 예측 된 차선의 수, N_pred는 예측된 차선의 수, M_pred는 missed G-T 차선의 수, N_gt는 모든 G-T 차선의 수입니다.
B. Setup
LaneNet은 δ_v = 0.5 및 δ_d = 3의 임베딩 차원 4로 훈련됩니다. 이미지는 512x256으로 크기가 조정되고 네트워크는 수렴 될 때까지 배치 크기가 8이고 학습률이 5*e(-4) 인 Adam을 사용하여 훈련됩니다.
H-Net은 차원이 128x64인 입력 이미지의 스케일링된 버전을 사용하여 3차 다항식 피팅을 위해 훈련되었습니다. 네트워크는 수렴 될 때까지 배치 크기가 10이고 학습률이 5*e(-5) 인 Adam을 사용하여 훈련됩니다.
Speed 512x256의 입력 해상도, 픽셀 당 4차원 임베딩 및 3차 다항식 맞춤을 사용하면 차선 감지 알고리즘을 초당 최대 50 프레임까지 실행할 수 있습니다. 다양한 구성 요소의 전체 분석은 표 IV에서 찾을 수 있습니다.
C. Experiments
Interpolation method
표 III에서는 no transformation, a fixed transformation and a conditional transformation based on H-net을 사용하여 차선 피팅의 정확도를 계산합니다. 또한 2차 또는 3차 다항식 피팅의 차이를 측정합니다. Transformation없이 원본 이미지 공간에 곡선을 직접 맞추면 결과가 나빠집니다. 곡선 차선은 저차 다항식을 사용하여 맞추기가 어렵기 때문입니다.
고정 변환을 사용함으로써 우리는 2차 다항식보다 3차 다항식에서 더 낫다는 결과를 이미 얻었습니다. 그러나 섹션 II-B에서 이미 언급했듯이 모든 차선 지점이 고정 변환으로 피팅 될 수 있는 것은 아닙니다 (그림 4 참조). Ground-plane의 기울기가 변경되면 소실점에 가까운 점을 올바르게 맞출 수 없으므로 MSE-측정에서 무시되지만 여전히 missed points로 계산됩니다.
차선 피팅에 최적화 된 H-Net에서 생성한 transformation matrix를 사용하면, 결과가 고정 변환으로 차선 피팅한것을 능가합니다. 더 나은 MSE-점수를 얻을 수 있을뿐만 아니라 이 방법을 사용하면 ground-plane의 기울기가 변경 되더라도 모든 점을 맞출 수 있습니다.


tuSimple results
3차 다항식 피팅과 H-Net의 변환 행렬과 결합된 LaneNet을 사용한 tuSimple 챌린지에서 첫번째 항목과 차이가 0.5 %에 불과하여 4 위에 도달했습니다. 결과는 표 II에서 볼 수 있습니다. 속도 성능과 마찬가지로 다른 항목에 대해서는 명확하지 않은 tuSimple 데이터 세트의 훈련 이미지에 대해서만 훈련했습니다.

IV. CONCLUSION
본 논문에서는 50fps의 종단 간 차선 감지 방법을 제시했습니다. 최근 인스턴스 세그멘테이션 기술에서 영감을 받은 이 방법은 다른 딥러닝 접근 방식과 달리 여러 차선을 감지하고 차선 변경에 대처할 수 있습니다.
저차 다항식을 사용하여 분할된 차선을 매개 변수화하기 위해, lane fitting이 optimal한 이미지에 대해 원근 변환의 매개 변수를 생성하도록 네트워크를 훈련했습니다. 이 네트워크는 lane fitting을 위한 custom loss function을 사용하여 훈련되었습니다. 널리 사용되는 "bird’s-eye view" 접근 방식과 달리 우리의 방법은 그에 따른 변환 파라미터를 조정하여 ground-plane’s slope change에 대해 강인합니다.
Acknowledgement: The work was supported by Toyota, and was carried out at the TRACE Lab at KU Leuven (Toyota Research on Automated Cars in Europe - Leuven).





