Real-Time Object Detection System with Multi-Path Neural Networks
Abstract
최근 DNN(Deep Neural Networks)의 발달에 힘입어 DNN 기반의 물체 감지 시스템은 매우 정확하고 자율주행차, 드론, 보안 로봇 등 실시간 환경에서 널리 이용되고 있다. 시스템은 차량 속도 등 실행 환경에 따라 달라질 수 있는 특정 시간 제한 내에 물체를 감지해야 하지만, 기존 시스템은 시간 제한 시간을 반영하지 않고 전체 long-latency DNN을 맹목적으로 실행하므로 실시간 제약을 보장할 수 없다. 이 작업은 GPU에서 DNN에 대한 새로운 WCET(worst-case execution time) 모델을 기반으로 multipath neural networks을 채택하는 새로운 실시간 객체 감지 시스템을 제안한다. 이 작업은 GPU에서 단일 DNN 계층 분석 프로세서와 메모리 경합에 대한 WCET 모델을 설계하고, 엔드투엔드 네트워크까지 WCET 모델을 확장한다. 또한 이 작업은 스킵, 스위치, 동적 생성 등 세 개의 새로운 오퍼레이터가 있는 다중 경로 네트워크와 대상 개체의 수를 동적으로 변경하는 제안서를 설계한다. 마지막으로, 이 작업은 동적으로 변화하는 환경과 시간 제약을 반영하여 런타임에 최적의 실행 경로를 선택하는 경로 결정 모델을 제안한다. 널리 사용되는 운전 데이터셋을 이용한 상세한 평가는 제안된 실시간 물체 감지 시스템이 시간 제한에 위반되지 않고 기준 물체 감지 시스템 못지않은 성능을 발휘한다는 것을 보여준다. 더욱이 WCET 모델은 각각 평균 27%와 81%의 오차에 불과한 컨볼루션 및 그룹 정규화 계층의 최악의 실행 지연 시간을 예측한다.
1. INTRODUCTION
물체가 어디에 있는지, 물체가 무엇인지 파악하는데 있어 Object Detection은 자율주행차, 드론, 보안 로봇에서 중요한 역할을 한다. 최근 DNN(Deep Neural Networks)의 발전 덕분에, 물체 감지 시스템은 전통적인 알고리즘[5], [6]보다 뛰어난 정확도를 제공하는 DNN[1]–[4]를 집중적으로 활용하기 시작한다. DNN 기반 객체 감지 시스템은 물체의 대표적인 특징을 추출하는 일련의 레이어들을 채택하여 식별 및 객체 분류의 정확도를 높인다.
DNN 기반 객체 탐지 시스템은 실행 환경에 따라 달라질 수 있는 실시간 제약을 준수해야 한다. 누락된 시간 제약이 충돌과 같은 대재앙을 야기할 수 있는 실시간 환경에서 시스템이 널리 채택되기 때문에, 시스템은 일정한 시간 제한 내에 물체를 감지해야 한다. 여기서는 실행 환경에 따라 시간 제한이 달라질 수 있다. 예를 들어, 자동차가 빠르게 달릴 때, 시스템은 충돌을 피하기 위해 앞쪽에 있는 물체를 빠르게 감지해야 한다. 반면에, 자동차가 느리게 달릴 때, 시스템은 차가 물체에 도달하는 시간이 증가하기 때문에 물체를 감지하는 시간이 더 길다. 따라서 DNN 기반 객체 감지 시스템은 시간 제한에 대해 알고 있어야 한다.
실시간 물체 감지 시스템의 한 가지 중요한 측면은 실행 latency와 정확도가 서로 충돌한다는 것이다. 첫째, 일반적으로 더 많은 계층을 가진 더 깊은 DNN은 더 많은 레이어를 가지고 있지만, 더 깊은 DNN은 더 높은 실행 지연을 초래하는 경향이 있다. DNN 기반 객체 탐지 시스템[1]–[4]은 콘볼루션 및 풀링(예: ResNet [7])과 같은 일련의 공간 작업을 통해 주어진 이미지에서 형상을 추출하고 평가하여 예측한다. 추가 레이어에 대한 부가적인 작업은 정확도를 높일 수 있지만 실행 지연 시간을 증가시킬 수도 있다. 둘째, 식별된 각 영역은 DNN을 실행해야 한다. 객체 탐지는 객체가 있을지 모르는 일련의 이미지 영역을 제안한다. 제안의 수가 많을수록 정확도가 향상되지만, 지역 제안의 수가 증가할수록 실행 지연 시간이 더 높아진다. 따라서 실시간 객체 감지 시스템은 다양한 시간 제약과 함께 지연 시간과 정확도 사이의 trade-offs를 반드시 인식해야 한다.
불행히도 기존의 DNN-based object detection systems[1]–[4]은 다양한 시간 제약 조건을 충족시킬 수 없다. Faster R-CNN [4] 및 Mask R-CNN [3]이 R-CNN [1] 및 Fast R-CNN [2]에 비해 훨씬 낮은 실행 대기 시간을 얻지만, 네트워크는 실시간 제약을 인식하지 못하고 종종 제한 시간을 초과한다. Dynamic model compression 및 DVFS[8]–[15]는 실행 지연 시간을 동적으로 조정할 수 있다. 그러나 model compression은 콘볼루션 레이어의 특정 필터를 분리하는 것으로 제한되며, DVFS는 전압과 주파수의 변화에 따른 엄청난 오버헤드로 인해 어려움을 겪기 때문에, 물체 탐지의 다양한 시간 제약을 효율적으로 충족할 수 없다. 마찬가지로 언제라도 알고리즘 [16]–[19]은 주어진 시간 제한에 따라 실행 경로를 변경하여 동적 시간 제약조건을 충족시킬 수 있지만, 적용 가능성은 단일 알고리즘으로 제한되어 있어 객체 탐지에 사용할 수 없다.
이 작업은 GPU의 DNN에 대해 새로운 WCET 모델을 기반으로 한 multi-path neural networks를 채용하는 새로운 실시간 물체 감지 시스템을 제안한다. multi-path neural networks는 각각 다른 latency-accuracy trade-offs를 갖는 여러 실행 경로를 제공하며, WCET 모델은 worst-case에 대해 각 경로의 예측된 지연시간들을 보여준다. 즉, 시스템이 시간 제약 조건을 충족하는 적절한 실행 경로를 동적으로 선택하고 실행할 수 있도록 한다. 이 작업은 시스템을 설계하고 구현하기 위해 먼저 GPU의 프로세서 및 메모리 경합에 대한 DNN의 단일 레이어에 대한 WCET 모델을 설계하고, WCET 모델을 엔드 투 엔드 네트워크까지 확장한다. 둘째, 이 작업은 스킵, 스위치, 동적 생성 제안 등 세 개의 새로운 오퍼레이터가 있는 다중 경로 네트워크를 설계하여 실행 경로를 동적으로 변경한다. skip operator는 시스템이 연속된 몇 개의 DNN 계층을 우회하도록 허용하고, switch operator는 시스템이 일련의 DNN 계층 중 하나를 선택하도록 하며, dynamic generate proposal은 대상 개체 영역의 수를 조정한다. 스킵 및 스위치 연산자는 대상 DNN의 여러 위치에 삽입되므로 시스템은 런타임에 나머지 실행 경로를 동적으로 조정할 수 있다. 마지막으로, 이 작업은 동적으로 변화하는 환경과 시간 제약을 반영하여 런타임에 최적의 실행 경로를 선택하는 경로 결정 모델을 제안한다.
이 작업에서는 제안된 실시간 객체 감지 시스템에 대한 실시간 인식을 입증하기 위해 잘 알려진 주행 데이터 세트를 사용하여 시스템을 교육하고 평가한다. Cityscapes[20] 및 BDD100K [21]. 평가 결과는 시스템이 기준 단일 경로 객체 탐지 시스템과 유사한 정확도를 달성하면서 마감 시간 누락 없이 시간 경과 시간 제약에 대한 객체 탐지 실행 경로를 적응적으로 변경한다는 것을 보여준다. 더욱이 평가 결과 WCET 모델은 평균 27%와 81%의 오류만으로 컨볼루셔널 및 그룹 표준화 계층의 최악의 실행 지연 시간을 예측하고 있다.
요약하면, 본 논문의 기여도는 다음과 같다.
- GPU에서 DNN 기반 개체 탐지를 위한 최악의 경우 실행 지연 시간 모델링
- 주어진 시간 제약에 따라 실행 경로를 적응적으로 변경하는 다중 경로 신경 네트워크
- 반사되는 다경로 신경망의 실행 경로를 동적으로 결정하는 경로 결정 모델 시간 제약의 변화
2. BACKGROUND & MOTIVATION
A. Deep Neural Networks for Object Detection
물체 감지 시스템은 매우 정확한 DNN의 혜택을 받을 수 있다. 물체 감지 네트워크는 크게 Single Shot Detector(SSD)[22]와 YOLO[23]–[25]와 같은 1단계 네트워크와 R-CNN[1], Faster R-CNN[3], Mask R-CNN[4]와 같은 2단계 네트워크로 분류할 수 있다. 1단계 네트워크와 2단계 네트워크의 주요 차이점은 region proposal과 classification steps가 분리되어 있는지 여부다. 1단계 네트워크는 추론 시간을 줄이기 위해 지역 제안과 분류 단계를 통합하는 반면, 2단계 네트워크는 객체 지역화를 개선하기 위해 지역 제안과 분류 단계를 분리한다. 이 연구는 두 가지 종류의 네트워크 중에서 2단계 네트워크에 초점을 맞춘다. 왜냐하면 2단계 네트워크는 동적 시간 제약 문제를 해결할 수 있는 더 많은 구성 가능한 특징을 가지고 있기 때문이다.
R-CNN[1]에 처음 사용된 2단계 객체 감지 네트워크는 먼저 유효한 객체를 포함할 수 있는 region proposals (i.e., bounding boxes)를 식별하고 region proposals에 유효한 객체를 분류한다. 이전 모델(예: R-CNN[1] 및 Fast R-CNN[2])에 비해 연산량이 적기 때문에 가장 널리 사용되는 two-stage 객체 감지 네트워크 중 하나인 Faster R-CNN[3]에 대한 간략한 배경을 예시로 제시한다.
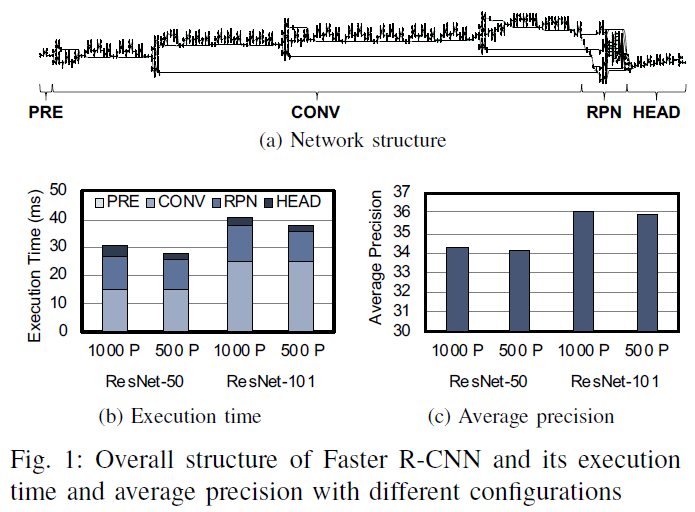
Faster R-CNN은 다음과 같은 4개의 주요 단계로 구성된다(그림 1(a)). - PRE, CONV, RPN and HEAD.
1) PRE는 주어진 영상에 스케일링, 자르기 등의 기본 루틴을 적용하여 DNN의 나머지 부분이 기대하는 것과 영상의 크기가 일치하도록 하는 전처리 단계다.
2) CONV에는 deep convolutional network(주로 ResNet [7])가 포함되어 있어 RPN 및 HEAD에 유용한 잠재 객체의 높은 수준의 특징을 추출한다.
3) RPN은 조사해야 할 이미지에서 특정 지역을 나타내는 region proposals을 제안하는 region proposal network를 포함한다.
4) HEAD는 후처리 단계로, 콘볼루션 네트워크로 고수준의 특징을 조사하여 RPN으로부터 각 영역의 객체를 최종적으로 분류한다.
Faster R-CNN은 이 작업이 target accuracy-latency trade-offs을 달성하기 위해 이용할 수 있는 다양한 구성 가능한 매개변수를 가지고 있다. 그림 1(b)과 그림 1(c)는 서로 다른 구성을 가진 간단한 Faster R-CNN 네트워크의 실행 시간 분석과 평균 정밀도를 보여준다. 여기에서 평균 정밀도(AP)는 물체 감지 시스템의 정확도를 평가하기 위한 측정기준을 나타낸다 [26]. AP는 유추된 bounding box가 ground truth bounding box와 정확히 겹치는 영상 영역의 평균 비율로 정의된다.
그래프는 객체 감지 네트워크의 정확도-지연성 트레이드오프를 명확하게 보여준다. 첫째, 그래프는 deeper CONV 단계(ResNet-101)가 shallower CONV 단계(ResNet-50)보다 더 많은 시간을 소비하면서 더 정확한 물체 감지 결과를 발생시킨다는 것을 보여준다. 마찬가지로 지역 제안(1000P)이 많을수록 지역 제안(500P)의 수가 적을 때보다 개체 탐지 네트워크의 정확도가 향상된다. 요약하면, CONV 단계의 깊이와 생성할 지역 제안의 수는 객체 감지 네트워크의 실행 시간과 정확성 모두에 영향을 미칠 수 있다. 이 작업은 이 속성을 사용하여 시간 변화를 일으키는 실시간 요구사항을 적응시키는 객체 감지 네트워크를 만든다.
B. Deep Neural Networks on Graphics Processing Units
Deep neural networks는 대량의 연산이 발생하기 때문에 낮은 실행 지연 시간을 달성하기 위해 높은 처리량을 요구한다. 고성능을 충족시키기 위해 CPU[27]보다 훨씬 높은 처리량을 제공하는 GPU(Graphics Processing Units)가 인기 있는 플랫폼이 되었다. GPU는 수천 개의 간단한 산술 코어와 고대역폭 오프칩 메모리를 가지고 있어 높은 처리량을 달성한다. GPU는 고정된 수의 GPU 코어(예: NVIDIA Turing GPU)를 갖는 스트리밍 멀티프로세서(SM)로 구성된다. 각 SM에는 워프 스케줄러, 레지스터 파일, 공유 메모리, L1 캐시가 있다. 워프 스케줄러는 각 SM의 스케줄링 세분화(예: NVIDIA GPU의 32개의 스레드/워프)인 와프 집합으로 스레드를 그룹화하고 동일한 워프 내에서 lock-setp 방식으로 스레드를 실행한다. 스레드가 메모리 액세스 요청을 실행하면 L1 캐시가 글로벌 L2 데이터 캐시 및 DRAM 메모리와 상호 작용하여 요청을 처리한다.
GPU의 높은 처리량을 충분히 활용하려면 프로그래머가 커널이라고 하는 GPU 친화적인 기능을 쓸 필요가 있다. 그런 다음 프로그래머는 하드웨어 리소스 집합을 공유하는 프로그래머가 지정한 스레드 수, 스레드 블록 크기, 총 스레드 수를 지정하여 GPU 커널의 실행을 시작할 수 있다. 동일한 스레드 블록 내의 스레드는 공유 메모리를 사용하기 때문에 GPU는 스레드 블록의 스레드를 특정 SM 전체에 할당한다. 커널에 의해 지정된 계산은 실행 중인 스레드 ID에 따라 다르므로, 스레드에 의한 커널의 병렬 실행은 단일 명령, 다중 스레드(SIMT - the Single Instruction, Multiple Threads) 실행 모델을 따른다 [28].
딥러닝의 급속한 성장으로 인해 GPU 벤더는 대표적인 DNN 운영을 구현하고 자사의 GPU에 최적화된 커널 세트를 제공한다(예: cuDNN [29]). 최적화된 커널을 호출함으로써 사용자는 목표 GPU에서 신경망의 레이어를 실행해 높은 처리량을 달성할 수 있다. DNN 라이브러리를 사용하여 딥러닝 프레임워크는 일반적으로 각 신경망 계층이 대량의 계산을 유발할 때 한 번에 GPU에서 한 레이어를 실행한다.
C. WCET Analysis for DNN Executions on GPUs
실시간 시스템은 실시간성을 보장하기 위해 대상 애플리케이션 및 플랫폼에 대한 WCET(최악의 경우 실행 시간) 분석을 요구한다. WCET 분석은 시스템의 가장 긴 실행 지연 시간을 계산하여 시스템의 실시간 인식을 검증한다. 대상 시스템에 대한 WCET 분석이 시스템 실행이 항상 주어진 시간 제한 내에 완료된다고 예측하는 경우, 우리는 시스템이 완전한 실시간 인식인지 검증할 수 있다. 시스템의 WCET를 예측할 때, naive하고 보수적인 WCET 분석은 시스템의 실행 지연 시간을 과대평가할 수 있지만, 실제 실행 레이턴시와 추정된 레이턴시의 갭을 최소화하면 시스템의 WCET를 더 정확하게 예측할 수 있기 때문에 실제 실행 지연 시간과 추정 실행 지연 시간 사이의 갭을 최소화하는 것이 바람직하다.
일부 이전 연구는 GPU 기반 실시간 시스템이 GPU의 실시간 인식[30], [31]을 평가할 수 있도록 GPU에 대한 WCET 분석을 수행한다. 불행히도, WCET 분석은 대상 애플리케이션의 소스 코드를 요구하고 GPU를 위한 대부분의 DNN 라이브러리는 독점적이기 때문에(예: NVIDIA의 cuDNN) GPU 기반 객체 감지 네트워크에 WCET 분석을 채택하기는 어렵다.
3. SYSTEM DESIGN
이 연구는 multi-path neural networks를 이용한 동적 시간 제약 조건을 만족시키는 실시간 객체 감지 시스템을 설계한다. 그림 2와 그림 3은 우리 시스템의 전체적인 디자인을 보여준다. 시스템이 동적 시간 제약 조건을 만족하도록 하기 위해, multi-path neural network는 시스템에 대체 실행 경로를 제공하는 스킵 및 스위치 연산자를 도입한다. 스킵 오퍼레이터는 시스템이 몇 개의 연속 레이어를 우회할 수 있도록 하고, 스위치 오퍼레이터는 시스템이 여러 레이어 중 최적의 실행 경로를 선택하게 한다. 런타임에서, multi-path neural networks는 스킵과 스위치 연산자를 통해 그리고 multi-path neural networks가 생성하는 지역 제안의 수를 동적으로 조정하여 적절한 실행 경로를 선택한다. 시스템은 적절한 실행 경로를 선택할 때 남은 시간 제한과 차량의 속도와 같은 동적 시스템 상태를 고려한다(그림 3). 시간이 촉박하면 multi-path neural networks은 더 짧은 실행 경로를 선택하고 소수의 지역 제안을 생성해 실행 지연 시간을 줄인다. 한편, 시간이 넉넉하면, multi-path neural networks는 더 긴 실행 경로를 선택하고 많은 수의 지역 제안을 생성함으로써 더 높은 정확도를 달성한다.


다경로 신경망을 설계하기 위해 시스템은 먼저 대상 플랫폼의 샘플 신경망을 프로파일링한다(그림 2). 우리 시스템은 기존의 객체 감지 네트워크[3]를 샘플 네트워크로 사용한다. 시스템은 필요한 프로파일링 결과를 수집하기 위해 대상 GPU에서 샘플 신경망을 여러 차례 실행함으로써 총 실행 주기 등 관련 성능 지표를 작성한다. 프로파일링 결과를 바탕으로 스킵과 스위치 오퍼레이터를 샘플 네트워크에 삽입하여 다경로 신경망을 생성한다. 그런 다음 시스템은 스킵 및 스위치 오퍼레이터의 잠재적 정확도 손실을 최소화하기 위해서 multi-path neural networks을 (re)train한다. 훈련 과정이 완료되면 시스템은 훈련된 multi-path neural networks을 대상 플랫폼으로 보낸다. 런타임 동안 시스템은 (1) multi-path neural network의 스킵 및 스위치 오퍼레이터를 활용하며, (2) multi-path neural network가 생성해야 할 지역제안 수를 동적으로 조정함으로써 동적 시간 제약조건을 만족시킨다. 남은 시간 제한에 따라, 스킵과 스위치 오퍼레이터는 시간 제한을 위반하지 않는 적절한 실행 경로를 선택한다. 오퍼레이터는 적절한 실행 경로를 선택할 때 WCET 모델을 활용하여 실행 경로의 실행 지연 시간을 예측한다. WCET 모델을 구축하기 위해 시스템은 single-layer 실행을 위한 인터벌 기반 WCET 분석을 채택하고 전체 다경로 신경망에 대한 WCET 분석을 확장한다. 이 시스템은 실시간 보증을 보장하기 위해 지역 제안의 수를 조정하기도 한다. 시스템이 시간이 부족할 때(i.e., the deadline is tight), 실행 지연 시간을 줄이기 위해 지역 제안의 수를 줄인다.
다경로 신경망과 WCET 모델을 채용함으로써 우리 시스템은 실시간 보증을 보장하고 물체 감지 정확도를 극대화한다. 스킵과 스위치 오퍼레이터는 동적 시간 제약 조건을 만족시키기 위한 대체 실행 경로를 제공한다. WCET 모델은 오퍼레이터가 동적 시간 제약 조건을 위반하지 않고 가능한 실행 경로 중 가장 높은 정확도를 달성하는 최적의 실행 경로를 선택할 수 있도록 한다.
4. WCET ANALYSIS FOR NEURAL NETWORKS
이 섹션에서는 WCET 분석과 함께 GPU 성능 모델을 제시한다. 우리의 실시간 객체 감지 시스템은 WCET 분석을 활용하여 실시간 보증을 보장한다.
A. Basic Assumptions
GPU에서 DNN의 실행 지연 시간을 모델링하기 위해, 우리는 우리의 목표 GPU 플랫폼에서 다음과 같은 주요 관찰을 한다.
첫째, Warp의 활성 스레드 수가 객체 탐지 DNN의 서로 다른 DNN 레이어에 대해 일정하다는 것을 관찰한다. 우리는 샘플 Fast R-CNN 네트워크의 콘볼루션 및 그룹 정규화 레이어를 실행할 때 NVIDIA 프로파일링 도구[34]를 사용하여 Warp 실행 효율성을 측정한다. 워프 실행 효율성은 워프에서 가능한 최대 활성 쓰레드에 대한 활성 쓰레드의 비율(즉, 워프 크기)을 나타낸다. 그림 4(a)는 NVIDIA GTX 1050Ti 및 NVIDIA Titan XP GPU에 대한 Warp 실행 효율의 누적 분포를 나타낸다. 각 계층마다 DNN 계층을 구현하는 GPU 커널은 항상 100% 와프 실행 효율성을 얻는다. 즉, 각 워프는 항상 프로세서가 지원하는 최대 활성 스레드 수를 가진다.

둘째, 각 SM은 메모리 경합이 없는 경우 실행 중에 적어도 하나의 활성 워프를 가지고 있다는 것을 알게 된다. NVIDIA 프로파일링 도구를 사용하여 사이클당 적용 가능한 평균 워프 수를 측정한다. 메트릭은 사이클당 다음 지침을 발행할 준비가 된 평균 워프 수를 나타낸다. 그림 4(b)에서 알 수 있듯이, 서로 다른 층의 약 97.7%가 평균적으로 사이클당 적격 워프를 1개 이상 가지고 있다. 프로파일링 결과를 토대로 각 SM이 메모리 경합이 존재하지 않을 경우 적어도 하나의 워프 일정을 항상 잡을 수 있다고 안전하게 가정할 수 있다. 메모리 경합은 워프 스톨을 유발하고 사이클당 적용 가능한 워프 수를 감소시키므로 이러한 가정에는 메모리 경합이 필요하지 않다는 점에 유의해야 한다.
셋째, 우리는 현재 GPU에서 가장 보편적인 Warp 스케줄링 정책인 the Greedy-Then-Oldest (GTO) warp scheduling policy에 초점을 맞춘다. GTO 정책은 워프가 멈출 때까지 워프의 지시를 계획한다. 스톨에서 가장 오랜 시간 동안 지시가 내려오지 않은 워프를 선정한다.
B. Single-layer Performance Modeling

DNN은 일련의 서로 다른 레이어로 구성되어 있기 때문에 DNN 성능 모델링을 위한 첫 번째 단계로 단층 성능을 먼저 모델링한다. 우리의 모델링은 Warp가 재조정된 시점부터 Warp가 정지된 후 Warp가 새로운 지시를 내릴 수 있는 시점까지 간격을 Warp의 지속 시간으로 정의하는 Interval 분석을 활용한다. 그림 5(a)에서 Cexec은 워프가 정지할 때까지의 실행 주기 수를 나타내고, Cstall은 워프가 명령을 내릴 준비가 될 때까지의 정지 주기 수를 나타낸다. 그 다음, Cexec과 Cstall이 interval i를 구성한다. Cexec과 Cstall은 워프가 다른 워프 또는 프로세서(즉 NVIDIA GPU의 SM)와 경합하지 않는다고 가정한다는 점에 유의한다.

표 I의 표기법을 사용하여 스레드 블록에 있는 모든 와프의 i번째 간격의 주기 수를 공식화한다.

GPU 스케줄러는 각 스레드 블록을 특정 프로세서에 할당하여 스레드 블록에서 여러 워프를 번갈아 실행한다. 그런 다음 Nproc 프로세서에서 Nblock 스레드 블록을 사용하여 단일 계층을 실행하는 총 사이클은 다음과 같이 된다.

그림 5는 사이클 수가 단일 워프 실행의 경우에서 추가 지연과 함께 다중 워프 실행의 경우로 어떻게 바뀌는지 보여준다.
1) Processor Contention Modeling : 프로세서 경합은 프로세서에 스케줄링할 여러 개의 활성 워프가 있을 때 발생할 수 있다. GTO 스케줄링 정책에 따라 프로세서는 워프가 멈출 때까지 워프를 욕심내서 실행한다. 그리고 나서, 정지된 워프는 새로운 지시를 내리기 전에 다른 워프들이 모두 멈출 때까지 기다린다. 그러한 경우 워프의 정지 주기 수가 다른 워프의 실행 주기 수보다 크면 그림 5(b)와 같이 프로세서 경합으로 인한 추가적인 지연은 없을 것이다. 반면에 워프의 정지 주기 수가 다른 워프의 실행 주기 수보다 작을 경우 워프는 SM이 그림 5(c)와 같이 이를 재조정할 때까지 추가 지연을 부담해야 한다.
우리의 두 번째 기본 가정에 기초하여, 프로세서는 준비된 워프들을 계속 재조정함으로써 정지 주기인 Cstall을 숨길 수 있다. 즉, 최악의 경우 일정이 조정될 때까지 워프는 (Nwarp - 1)워프를 기다려야 한다. 요약하면 프로세서 경합으로 인한 최악의 추가 지연은 다음과 같다.

2) Memory Contention Modeling : 메모리 경합은 여러 프로세서가 DRAM에 액세스하거나 여러 스레드가 동일한 공유 메모리 뱅크에 동시에 액세스할 때 발생할 수 있다. 이 경우 추가 지연은 다음과 같다.

(i) MSHR Contention : MSHR은 메모리 주소와 같은 캐시 미스 정보를 사용하여 캐시 미스를 처리하는 레지스터다. MSHR 경합은 MSHR의 수가 제한되기 때문에 추가적인 지연을 초래할 수 있다. 이전 연구[35]의 MSHR 경합 모델에 기초하여, NUM_MSHR이 MSHR의 수인 최악의 MSHR 경합을 고려하여 모델을 단순화한다.

(ii) DRAM Bandwidth Contention: 여러 프로세서가 동시에 off-chip DRAM에 접속하면 DRAM 대역폭은 메모리 요청 처리를 제한한다. 마찬가지로, 기존 DRAM 경합 모델[35]을 다음과 같이 단순화한다. 여기서 Core FREQ는 핵심 주파수, CASH LINE은 캐시 라인 크기, MEM BAND는 DRAM 대역폭인 최악의 경우 대역폭 경합(즉, DRAM 활용도가 매우 높음).

(iii) Shared Memory Bank Contention : 공유 메모리는 동일한 스레드 블록의 스레드가 공유할 수 있는 on-chip 스크래치패드 메모리 공간이다. 처리량을 극대화하기 위해 각 프로세서는 여러 개의 공유 메모리 뱅크가 있는 공유 메모리를 가지고 있어서 워프의 모든 스레드가 동시에 다른 뱅크에 접근할 수 있다. 이 경우, 공유 메모리(Dbank)의 공유 메모리 뱅크에 접속하기 위한 추가 지연은 뱅크 충돌이 발생하지 않기 때문에 zero일 뿐이다.
그러나, 스레드가 같은 뱅크에 접근할 때, 뱅크 충돌이 발생할 수 있고 접속이 직렬화된다. 모든 스레드가 동일한 공유 메모리 뱅크에 액세스하는 최악의 경우, 스레드는 은행에 액세스하기 전에 (Rs-1)을 기다려야 한다. 그런 다음 공유 메모리 뱅크 경합으로 인한 최악의 추가 지연은 다음과 같다.

추가 지연을 계산할 때 요청의 공유 메모리 액세스 지연 시간을 뺀다는 점에 유의해야 한다. 이 지연 시간은 이미 스톨 사이클(Cstall i )로 계산되어있다.
요약하면, 싱글레이어를 실행하기 위한 전체 사이클 수는 다음과 같다.
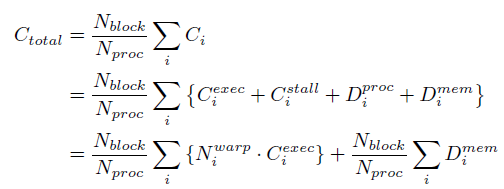
여기서 우리의 성능 모델은 GPU가 다른 애플리케이션을 실행하는 동안 각 레이어의 실행 지연 시간을 정확하게 예측할 수 있다. GPU는 SM을 다른 애플리케이션에 분산시켜 공간 멀티태스킹을 지원하므로, 이러한 멀티 테넌트 시나리오에서 실행 지연 시간을 정확하게 예측하려면 SM당 동작의 정확한 모델링이 필요하다. 우리 방식은 구간 개념을 이용해 SM당 모델링 정확도를 높이고, DNN 간에 공유되는 DRAM 대역폭 소모를 모델링한다. 따라서, 정밀도가 높은 두 모델을 사용하면 멀티 테넌트 시나리오에도 적용할 수 있도록 성능 모델을 쉽게 확장할 수 있다.
C. WCET Analysis
본 연구는 성능 모델링에 기초하여 GPU의 심층 신경망에 대한 WCET 분석 방법론을 설계한다. 성능 모델에서 최악의 실행 시간을 얻으려면 성능 모델에서 알 수 없는 파라미터를 결정해야 한다. GPU 아키텍처의 전체 사양은 일반에게 공개되지 않기 때문에, 우리는 다른 구성을 가진 계층들의 프로파일링 결과에 기초하여 선형 회귀를 통해 매개변수를 찾는다. 표 II에는 평가에 사용하는 NVIDIA 프로파일링 툴 [34]의 이벤트 및 메트릭이 나열되어 있다.

가정 1 : 총 실행 주기는 계산, 부하 및 저장 명령 수와 선형 관계를 갖는다.

가정 2 : 총 메모리 요청은 부하 및 저장 명령 수와 선형 관계를 갖는다.
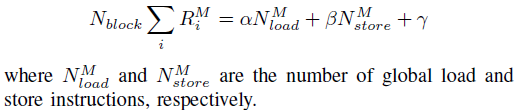
가정 3: 총 공유 메모리 요청은 공유 로드 및 저장 명령 수와 선형 관계가 있다.

다른 알려지지 않은 파라미터(즉, LM과 LS)에 대해서는, 공유 메모리 처리량, DRAM 처리량과 같은 NVIDIA 프로파일링 툴[34]의 아키텍처 분석 [36], [37] 및 다른 레이어의 프로파일링 결과를 참조하여 각 파라미터의 최악의 경우를 추정한다.
D. Extending to End-to-End Network
End-to-end 네트워크에는 레이어 실행 외에 전처리 또는 후처리 계산이 포함되지만, 전처리 및 후처리 시간은 엔드투엔드 네트워크 지연의 작은 비율을 만든다. 따라서 우리는 단순 회귀 모델을 사용하여 레이어 사이의 최악의 경우 전처리 및 후처리 시간을 확률적으로 추정한다. 마지막으로, WCET 분석 방법을 사용하여 경로에 있는 계층의 최악의 경우 실행 시간과 계층 간의 전처리 및 후처리 시간을 합산하여 엔드투엔드 네트워크 지연 시간을 추정할 수 있다.
5. MULTI-PATH OBJECT DETECTION NETWORK
A. Network Design
신경 네트워크가 동적 시간 제약 자체를 인식하도록 하기 위해, 본 연구는 스킵, 스위치, 동적 생성 제안의 세 가지 새로운 연산자를 소개한다. 그림 6은 입력과 출력을 가진 세 운영자를 보여준다. 먼저 스킵 오퍼레이터(그림 6(a))는 단일 서브넷(레이어 집합)을 포함하고 상대적 마감일에 따라 서브넷의 실행 여부를 결정하고 임계값을 생략한다. 둘째, 스위치 오퍼레이터는 여러 서브넷을 포함할 수 있으며 (그림 6(b))는 상대적 마감일에 따라 실행할 서브넷 중 하나를 선택하고 서브넷에 대한 스위치 임계값을 선택한다. 셋째, 동적 생성 제안 사업자(그림 6(c))는 상대적 마감일 및 제안 문턱값에 따라 HEAD 단계로 넘어갈 지역 제안의 수를 결정한다. 섹션 V-B는 경로 결정 모델이 각 운영자의 임계값을 결정하는 방법을 설명한다.

3개의 연산자를 이용하여, 우리 시스템은 기존의 객체 감지 네트워크 위에 다경로 객체 탐지 네트워크를 구축한다 [3], [4]. 기존의 객체 감지 네트워크는 네트워크를 구성할 수 있는 다양한 설계 공간을 제공한다. 첫째로, 네트워크는 CONV 단계에서 다른 수의 레이어를 가질 수 있다. 둘째, 네트워크는 다른 수의 지역 제안을 생성할 수 있다. 셋째, 네트워크는 분류 정확도에 영향을 미치는 HEAD 단계에서 다른 수의 숨겨진 채널로 다른 수의 컨볼루셔널 블록을 가질 수 있다.
세 개의 네트워크 설계 공간을 탐색하면서, 이 연구는 동적으로 경로를 변경할 수 있는 다중 경로 객체 탐지 네트워크를 설계한다. 우선, 시스템은 그림 1(a)와 같이 일반적으로 매우 깊은 CONV 단계에 스킵 연산자를 삽입한다. 스위치 운영자는 각 서브넷에 대해 개별 weight 매트릭스를 유지해야 하기 때문에 메모리 사용 측면에서 스위치 운영자보다 스킵 운영자가 더 적합하다.
CONV 단계의 경우, 본 연구는 객체 감지 네트워크를 위한 가장 일반적인 백본 네트워크 중 하나인 ResNet[7]을 다루고 있다. ResNet은 여러 개의 residual 단계로 구성되며, 각 residual 단계는 동일한 residual 블록을 포함한다. ResNet은 같은 단계에서 동일한 입력 차원을 유지하므로, ResNet은 원래 네트워크에 대한 추가 오버헤드 없이 스킵 연산자를 쉽게 적용할 수 있다. VGG [38]과 같은 다른 컨볼루션 신경망의 경우, 스킵 연산자를 추가하면 출력 및 입력 치수와 일치하기 위해 추가 레이어가 필요할 수 있다. 따라서 그러한 네트워크는 다중 경로 객체 감지 네트워크에는 덜 적합하다. 그림 7(a)는 시스템이 CONV 단계에서 여러 스킵 연산자를 추가하는 방법을 보여준다.
다음으로, 본 연구는 RPN 단계를 확장하여 기존 생성 제안 오퍼레이터를 동적 생성 제안 오퍼레이터로 대체함으로써 요구에 맞게 지역 제안의 수를 동적으로 변경한다. 동적 생성 제안 운영자는 지역 제안의 수를 동적으로 변경할 수 있으며, 이는 HEAD 단계의 입력의 배치 크기를 결정한다. 경로 결정 모델은 동적 생성 제안 운영자가 적절한 수의 지역 제안을 찾을 수 있는 임계값을 제공한다.
마지막으로 시스템은 HEAD 단계에 대해 여러 개의 콘볼루션 서브넷을 생성한다. HEAD 단계는 일반적으로 CONV 단계보다 훨씬 낮은 수준의 컨볼루셔널 네트워크를 포함한다. 따라서, 여러 서브넷을 유지하는 것은 HEAD 단계에 대해 허용된다. 또한 HEAD 단계는 객체 감지 네트워크의 최종 예측 결과를 결정하는 완전 연결 레이어를 포함한다. 그런 다음 서로 다른 서브넷 간에 완전히 연결된 계층을 공유하면 서로 다른 실행 경로에서 출력 예측 결과가 오염될 수 있다. 따라서 시스템은 여러 서브넷을 생성하고 각 서브넷을 서로 다른 수의 콘볼루션 블록과 숨겨진 레이어 치수로 구성한다. 그림 7(b)는 시스템이 HEAD 단계에서 스위치 오퍼레이터를 추가하는 방법을 보여준다.

시스템은 다음 두 가지 제약을 충족시키기 위해 기존 객체 감지 시스템의 구성 가능한 매개변수[39]를 기반으로 다중 경로 네트워크를 구성한다.
1) 데드라인 제약 조건 : 다중 경로 네트워크의 최대 실행 시간(tT max)은 최대 상대적 데드라인(Dmax)보다 작거나 같아야 한다.

2) 메모리 제약 조건: 다중 경로 네트워크에 필요한 총 메모리는 대상 플랫폼의 총 메모리(Mmax)보다 작거나 같아야 한다.

여기서 n은 네트워크의 서로 다른 계층의 수이고 Mi는 각 계층이 필요로 하는 메모리의 양이다.
데드라인 제약 조건과 메모리 제약 조건을 모두 만족시키는 다중 경로 네트워크 모델을 얻기 위해, 시스템은 최소 객체 감지 네트워크로부터 시작하여 점차 네트워크를 확장한다. 최소한의 바람직한 정확성을 보장하기 위해, 시스템은 다중경로 객체 감지 네트워크에 대해 ResNet의 처음 몇 개의 레이어와 같은 몇 개의 필요한 네트워크 레이어를 보존한다. 그 후, 시스템은 매개변수가 기존의 객체 감지 네트워크를 참조하는 제약조건 중 하나를 위반할 때까지 네트워크에 residual 블록이나 convolutional 블록을 점진적으로 삽입한다.
시스템은 정확성 손실을 줄이기 위해 설계 정책에 따라 전체 네트워크 구조를 자동으로 구성한다. 첫째, 시스템은 원래 ResNet 구조를 모방하는 CONV 단계에서 컨볼루셔널 블록을 가진 스킵 연산자를 추가한다(즉, ResNet-50 및 ResNet-101). 그런 다음, 시스템은 훈련 데이터 세트가 충분히 크지 않을 경우 너무 깊은 나머지 네트워크가 좋은 성능을 얻지 못할 수 있기 때문에 CONV 단계가 ResNet-101만큼 깊어진 후 HEAD 단계에 여분의 서브넷을 가진 스위치 오퍼레이터를 삽입한다. 사용 가능한 메모리 공간이 여전히 사용 가능한 경우 시스템은 스위치 운영자에 더 작은 서브넷을 추가한다.
B. Path Decision Model
네트워크 구조로, 경로 결정 모델은 각 오퍼레이터가 데드라인까지 남은 시간에 따라 어떻게 행동해야 하는지를 결정한다. 각 오퍼레이터는 추론 작업이 시작되는 시점부터 경과된 시간(te)을 확인하고, 결국 데드라인(D)을 충족시키기 위해 적절한 결정을 내린다. 각 연산자는 te의 실시간 값을 추적한 다음, 각 연산자는 객체 감지 네트워크의 실행과 함께 te의 다른 값을 관찰한다는 점에 유의한다.
C. Training Multi-path Neural Networks
이 연구는 다중 경로 신경망을 경험적으로 훈련시키기 위한 효율적인 전략을 찾으려고 한다. 경사가 항상 모든 경로로 전파되는 정적 신경망과 달리 다중경로 신경망은 경사가 전파될 수 있는 여러 개의 가능한 경로를 가지고 있다. 네트워크 구조(즉, 스킵 및 스위치 운영자의 수)에 따라 가능한 경로의 수가 엄청날 수 있다. 따라서 효율적인 훈련 전략을 찾는 것은 다경로 신경망을 이용하는 데 있어 하나의 난제다.
우리는 스킵과 스위치 오퍼레이터를 위해 서로 다른 훈련 전략을 설계하고, 다음 네 가지 훈련 전략으로 동일한 다경로 신경망을 훈련시켜 최선을 찾는다.
• No Skipping - No Switching (NS-NS) : 각 skip operator의 서브넷을 건너뛰지 않고 실행하고 각 switch operator에 대한 모든 서브넷의 결과를 집계한다.
• Random Skipping - No Switching (RS-NS) : 각 skip operator의 서브넷을 임의로 실행하고 각 switch operator의 모든 서브넷의 결과를 집계한다.
• No Skipping - Random Switching (NS-RS) : 각 skip operator의 서브넷을 건너뛰지 않고 실행하고 각 switch operator에 대해 단일 서브넷을 임의로 실행
• Random Skipping - Random Switching (RS-RS) : 각 skip operator의 서브넷을 임의로 실행하고 각 switch operator에 대해 단일 서브넷을 임의로 실행
실행 경로를 무작위로 선택할 때 다중 경로 신경망은 반복(전방 및 역방향 통과 한 쌍)당 경로를 랜덤하게 변경한다는 점에 유의해야 한다. 즉, 다중경로 신경망은 구배가 잘못된 경로를 통해 전파되는 것을 방지하기 위해 반복 내에서 특정 경로에 붙는다.
표 IV는 각 훈련 전략을 적용할 때 최대 AP를 보여준다. 우리는 Cityscape 데이터 집합[20]으로 빈 다중 경로 네트워크를 훈련시키고 다중 경로 네트워크의 가장 긴 경로를 실행함으로써 최대 AP를 측정한다. 4가지 교육 전략 중 NS-RS와 RS-RS가 NS-NS와 RS-NS보다 더 높은 정확도를 획득한다. 결과는 무작위로 전환하느냐 마느냐가 정확도에 상당한 영향을 미친다는 것을 암시한다. 우리는 이러한 정확성 손실이 aggregation operator(집계 운영자)에 의한 vanishing gradient problem(소멸 구배 문제)에서 발생할 수 있다고 가정한다. 반면 무작위로 건너뛸지, 아니면 의미 있는 정확도를 유발하지 않을지는 No Switching에 의해 바뀐다.

6. EVALUATION
실시간 객체 감지 시스템을 평가하기 위해 본 작업은 Cafe2 딥러닝 프레임워크와 Detectron 객체 감지 시스템 위에 프로토타입 시스템을 구현한다[39]. 우리는 카페2를 확장하여 그림 6에 나타낸 다경로 신경망의 3개 연산자를 지원하고, Detectron은 다중경로 신경망을 만들고 타이머 연산자를 만들어 각 연산자를 실행하기 전에 경과된 시간을 점검한다. 우리는 ResNet-101 및 FPN과 함께 그룹 표준화 레이어를 기본 네트워크로 채택한 Faster R-CNN 네트워크를 사용한다. 베이스라인 네트워크 위에, 5개의 스킵 연산자와 1개의 스위치 연산자를 베이스라인 네트워크에 삽입하여 멀티패스 네트워크를 구축한다. 스킵 오퍼레이터를 위한 25개의 잠재적 포지션 중, 우리는 시간 변동의 마감 시한과 오버헤드 건너뛰기에 적응하기 위해 의미 있는 스킵 간 지연 시간을 고려하여 5개의 포지션을 선택한다.
네트워크를 교육하고 테스트하기 위해 우리는 널리 사용되는 두 가지 주행 데이터셋을 사용한다. : Citiscapes[20] 및 BDD100K [21]. Cityscape 데이터 집합의 경우, 우리는 질좋은 트레이닝 셋을 사용하고 이전 작업에서와 같이 소형의 범주를 사용한다[4]. 표 V는 데이터셋의 특성과 우리가 사용한 트레이닝 매개변수를 요약한다. 기본 네트워크와 다중 경로 네트워크 모두에 대해 표 V에서 동일한 교육 반복을 시행한다는 점에 유의해야 한다. NVIDIA Titan XP GPU를 객체 감지 시스템의 타깃 플랫폼으로 활용한다.

A. Real-time Object Detection Using Multi-path Networks
이 실험에서는 우리의 실시간 객체 감지 시스템이 동적 시간 제약 조건을 만족시킬 수 있는지 여부를 평가한다. 구체적으로, 실험은 다중 경로 신경 네트워크가 WCET 모델을 이용하여 동적 시간 제약에 보수적으로 적응할 수 있는지 여부를 검토한다. 또한, 이 실험은 메모리 경합 모델링 없이 다경로 신경망의 실행을 검사한다. 메모리 경합성 지연 시간 추정 모델은 실행 경로를 선택할 때 WCET 분석에서 가정 1의 선형 관계만 채택한다. 실험은 시간이 지남에 따라 차량의 속도가 동적으로 변화하는 주행 시나리오를 가정한다. 허용된 추론 시간(즉, 실시간 물체 감지 시스템의 제한 시간)은 차량 속도에 따라 변경된다.
실험 결과는 WCET 모델을 사용하는 우리의 시스템이 동적 시간 제약조건을 완전히 만족한다는 것을 분명히 보여준다. 반면에 memory comtention-oblivious 모델 기반 실행은 동적 시간 제약 조건을 위반하는 실시간 보장을 보장하지 못한다. 그림 8은 WCET 모델에서 메모리 경합 모델링이 없거나 또는 없는 다중 경로 신경 네트워크 실행 지연 시간을 보여준다. 우리 시스템은 WCET 모델을 이용한 다중 경로 신경망의 실행이 항상 데드라인 전에 끝나기 때문에 완전히 실시간 인식되고 있다. 그러나 적절한 안전 마진을 찾는 데 도움이 되는 메모리 경합 모델링이 없으면 다경로 신경망은 종종 기한을 맞추지 못한다.

시간제한이 변화함에 따라 다경로 신경망의 추론 정확도 변화도 평가한다. 그림 9에 나타난 평가 결과는 우리의 다중경로 신경망은 제한 시간이 빡빡하게 되어도 정확도 손실이 거의 발생하지 않는다는 것을 보여준다; 우리의 시스템은 cityscape와 BDD100K의 유효화 세트에 대해 각각 3.1 과 1.1 포인트 미만의 정확도 손실을 유발한다. 다중 경로 네트워크의 경우, 메모리 경합 모델링이 있거나 없는 WCET 모델을 모두 채택하고 있다. 메모리 경합성 지연 시간 추정 모델은 비슷한 정확도 손실을 유발하지만, 우리의 전체 WCET 모델은 거의 정확도 손실을 유발하지 않을 뿐만 아니라 실시간성을 보장한다.
요컨대 WCET 모델을 가진 우리의 다중 경로 신경망은 거의 정확도 손실 없이 실시간 물체 탐지를 가능하게 한다. 그러나 메모리 경합-확실성 모델은 추론 지연 시간을 너무 엄격하게 추정하기 때문에 동적 시간 제약 조건을 완전히 만족시키지 못한다.
B. Accurate Single-layer WCET Analysis
이제 우리는 단일 레이어 WCET 분석의 정확성을 평가한다. 우리 시스템은 실시간 보장을 위해 단일 레이어 WCET 분석에 의존하기 때문에 정확한 단일 레이어 WCET 예측을 달성하는 것은 필수적이다. 이 실험을 위해 우선 두 개의 단일 레이어 신경망을 구축하는데, 각각은 카페2 위에 컨볼루션 레이어와 그룹 노멀라이제이션 레이어가 있다. 그런 다음 두 뉴럴 네트워크를 다양한 구성(예: 입력 크기)으로 프로파일링하여 두 종류의 층에 대한 단일 레이어 WCET 모델을 얻는다. 그 후, 단일 레이어 WCET 모델은 실제 하드웨어 플랫폼에 대해 검증되고 메모리 경합 모델링이 없는 WCET 모델과 비교된다. WCET 모델의 플랫폼 이식성을 평가하기 위해 NVIDIA GTX 1050 Ti GPU와 Jetson TX2를 추가 타깃 플랫폼으로 채용하고 있다.
실험 결과는 우리의 단일 계층 WCET 모델이 단층 실행 지연 시간을 정확하게 예측한다는 것을 보여준다; Titan XP, GTX 1050Ti, Jetson TX2의 경우, 컨볼루셔널 계층에 대한 최대 절대 오류는 각각 0.06ms, 0.38ms, 2.68ms에 불과하다. 그림 10은 타이탄 XP, GTX 1050Ti, Jetson TX2의 2개 층의 실제 실행 시간과 추정 실행 시간을 나타낸다.

에러바는 5개의 프로파일링 실행에서 최소 및 최대 실행 시간을 나타낸다. 평균적으로, 컨볼루션 레이어용 WCET 모델은 최대 실행 시간에 걸쳐 타이탄 XP, GTX 1050Ti, Jetson TX2에서 각각 27%, 35%, 85%의 상대적 오류를 얻는다. 그룹 표준화 계층의 경우, 최악의 경우 실행 시간 모델은 타이탄 XP, GTX 1050Ti, Jetson TX2에서 각각 81%, 44%, 223%의 상대적 오류를 얻는다. 메모리 경합-확실성 모델은 더 작은 예측 오류를 발생시키는 경향이 있지만 WCET를 고려하지 않으며 많은 경우에 WCET를 보장할 수 없다. WCET 분석의 오류는 다중 경로 신경망의 실행을 통해 누적되지 않으며, 각 오퍼레이터는 WCET 대신 실제 경과 시간을 동적으로 추적한다.
또한 레이어를 실행하는 동안 다른 GPU 커널을 병렬로 실행하여 멀티 테넌트 시나리오에서 WCET 모델을 평가한다. 그림 11은 1-tenant 시나리오와 2-tenant 시나리오에서 Titan XP의 실제 및 추정 실행 시간을 보여준다. 그림 11에서 GPU 활용률은 다른 테넌트가 사용하는 멀티프로세서의 평균 비율을 나타낸다. 우리는 적어도 평가된 결과에 대해 시간 제약 조건을 위반하지 않도록 실험에서 실제 실행 시간과 추정 실행 시간 사이의 최대 상대 오차(45%)로 Memory Contention-Oblivious 모델의 안전 마진을 설정했다. 평균적으로 WCET 모델은 컨볼루셔널 및 그룹 표준화 레이어에 대한 안전 여유도를 가진 메모리 경합성 모델에 비해 각각 51%와 3%의 오류를 적게 얻는다. 결과는 WCET 모델이 멀티 테넌트 시나리오에서 오류가 더 적은 WCET를 추정하는 반면 메모리 경합이 심한 모델은 안전 여유도에서도 실행 시간을 제대로 추정하지 못할 수 있다는 것을 보여준다.

8. CONCLUSION
실시간 물체 감지 시스템은 환경변화의 시간 제약조건을 만족시켜야 하지만, 높은 정확도를 달성하기 위해 DNN을 채택한 기존의 물체 감지 시스템은 실시간 요건을 충족하지 못한다. 이 논문은 multi-path neural networks를 사용한 새로운 실시간 물체 감지 시스템과 neural networks를 위한 WCET 성능 모델을 제안한다. 네트워크는 다양한 시간 제약 조건을 충족시키기 위해 그들의 실행 경로를 동적으로 선택할 수 있다. 널리 사용되는 주행 데이터셋을 사용한 상세한 실험은 시스템이 높은 정확도를 유지하면서 어떤 시간 제한도 성공적으로 충족한다는 것을 분명히 보여준다.



